

索引是什么?索引是提高查詢性能的一個重要工具,索引就是把查詢語句所需要的少量數據添加到索引分頁中,這樣訪問數據時只要訪問少數索引的分頁就可以。但是索引對于提高查詢性能也不是萬能的,也不是建立越多的索引就越好。索引建少了,用WHERe子句找數據效率低,不利于查找數據。索引建多了,不利于新增、修改和刪除等操作,因為做這些操作時,SQL SERVER除了要更新數據表本身,還要連帶地立即更新所有的相關索引,而且過多的索引也會浪費硬盤空間。因此要建得恰到好處,這就需要經驗了。
一:索引的基本目的
索引的基本目的是在大量數據中找尋少量數據。你可以想像一下,若一本書有700頁,就像數據表有700個數據頁,而索引卻有600個索引頁,你會想用索引來查詢書籍的內容嗎?
索引字段的值重復性越低越好,假設書籍中如“的”“了”這些在文章中重復性極高的字,每頁都有一大堆,你會先翻索引頁某個位置有“的”,翻回該頁讀取了“的”之后,再索引看下一個“的”,結果是在先前同一頁的不同位置,又翻回書籍原頁查看下一個“的”。
那么怎么理解索引是從大量數據中尋找少量數據呢?下面我們舉個例子來說明。
如果一個數據表的記錄平均長度為400字節,則100萬條記錄需要5萬個數據頁,其計算公式如下:
1000000/(8060/400)=50000
如果該數據表建立聚集索引,鍵值為4個字節長度,而ID的數據長度為13個字節,因此索引結構每條記錄為20個字節。
4(聚集索引鍵值)+13(ID鍵值)+3(管理信息)=20
以ID字段所建立的索引,100%填充率,則總分頁數約為2482頁,其計算方式如下:
1000000/(8060/20)
即使是使用80%的填充率來計算也只有3106頁。其計算方式如下:
1000000/((8060*0.8)/20)
從上面可以看出如果是第一種情況,則索引頁只占到總數據頁的5%:
2482/50000=0.04964
即使考慮取每頁只填充80%的索引數據,第二種情況,索引頁也只是占總數據頁的6%:
3106/50000=0.06212
再說如果查詢條件中的字段建立索引,則由于索引鍵值數據都是以B-Tree有順序的擺放,所以可采用二分查找找數據。也就是2的N次方大于記錄數,就可以找到該條數據。而2的20次方大于100萬,因此最多找尋20次就可以找到該條記錄。由于比較次數少,數據結構也小,節省訪問硬盤與內在的資源,索引將大幅提升找尋數據的效率。SQL SERVER為提高訪問與查找對比的效率,用來作索引的數據域鍵值愈小愈好,也就是要讓分頁盡量存更多的鍵值記錄。
注:
如果未使用 UNIQUE 屬性創建聚集索引,數據庫引擎將向表自動添加一個 4 字節的 uniqueifier 列。必要時,數據庫引擎將向行自動添加一個 uniqueifier 值以使每個鍵唯一。此列和列值供內部使用,用戶不能查看或訪問。
二:什么是索引
在 SQL Server 中,索引是按 B 樹結構進行組織的。如下圖。

您也可以把索引理解為一種特殊的目錄。微軟的SQL SERVER提供了兩種索引:聚集索引(clustered index,也稱聚類索引、簇集索引)和非聚集索引(nonclustered index,也稱非聚類索引、非簇集索引)。下面,舉例來說明一下聚集索引和非聚集索引的區別:
其實,新華字典的正文本身就是一個聚集索引。比如,我們要查“按”字,就會很自然地翻開字典的前幾頁,因為“按”的拼音是“an”,而按照拼音排序的新華字典是以英文字母“a”開頭并以“z”結尾的,那么“按”字就自然地排在字典的前部。如果您翻完了所有以“a”開頭的部分仍然找不到這個字,那么就說明新華字典中沒有這個字;同樣的,如果查“招”字,那也會將新華字典翻到最后部分,因為“招”的拼音是“zhao”。也就是說,新華字典的正文部分本身就是一個目錄,您不需要再去查其他目錄來找到您需要找的內容。我們把這種正文內容本身就是一種按照一定規則排列的目錄稱為“聚集索引”。
如果您碰到一個不認識的字,不知道它的發音,這時候,您就不能按照剛才的方法找到您要查的字,而需要去根據“偏旁部首”查到您要找的字,然后根據這個字后的頁碼直接翻到某頁來找到您要找的字。但您結合“部首目錄”和“檢字表”而查到的字的排序并不是真正的正文的排序方法,比如您查“張”字,我們可以看到在查部首之后的檢字表中“張”的頁碼是672頁,檢字表中“張”的上面是“馳”字,但頁碼卻是63 頁,“張”的下面是“弩”字,頁面是390頁。很顯然,這些字并不是真正的分別位于“張”字的上下方,現在您看到的連續的“馳、張、弩”三字實際上就是他們在非聚集索引中的排序,是字典正文中的字在非聚集索引中的映射。我們可以通過這種方式來找到您所需要的字,但它需要兩個過程,先找到目錄中的結果,然后 再翻到您所需要的頁碼。我們把這種目錄純粹是目錄,正文純粹是正文的排序方式稱為“非聚集索引”。
通過以上例子,我們可以理解到什么是“聚集索引”和“非聚集索引”。進一步引申一下。
聚集索引
聚集索引指的是數據表本身就是索引的一部分,就是指數據表本身就是聚集索引的子葉層,整個數據表的擺放順序是按照你選定的鍵值由小到大排序,SQL SERVER 2000 之后的版本可指定數據由大到小排序。
整個數據表按照鍵值字段由小到大排序,再搭配由鍵值字段加上指針的上層索引結構,也就是根節點和非子葉層級,形成整個聚集索引。因為數據表內實際擺放數據的方式只能遵循一種順序,所以一個數據表只能有一個聚集索引。在指定聚集索引時,數據域本身并不需要唯一,或指定為唯一的聚集索引,SQL SERVER內部會自動為重復的鍵值建立4個字節的唯一標識。
如果你的數據表有一列常常用來排序,另一列常常用來 范圍查詢,還有一列重復性非常高,則該用哪一列來做聚集索引。正確答案是依據哪個查詢最重要,最常被用戶執行。例如:你的老板一小時內多次執行某個查詢當然比一個月執行一兩次的查詢來得重要。
表(堆)創建聚集索引或刪除和重新創建現有聚集索引時,要求數據庫具有額外的可用工作區來容納數據排序結果和原始表或現有聚集索引數據的臨時副本。
當堆或聚集表具有多個分區時,每個分區都有一個堆或 B 樹結構,其中包含該指定分區的行組。例如,如果一個聚集表有 4 個分區,那么將有 4 個 B 樹,每個分區一個。
聚集索引( Clustered Index)
· 聚集索引的葉節點就是實際的數據頁
· 在數據頁中數據按照索引順序存儲
· 行的物理位置和行在索引中的位置是相同的
· 每個表只能有一個聚集索引
· 聚集索引的平均大小大約為表大小的 5%左右
要使用索引來更有效地排序查詢數據,最直接的方式就是在你要排序的字段上建立聚集索引。在建立聚集索引之后,SQL SERVER會重新組織數據頁,讓其中的數據行按照聚集索引中鍵值的順序存儲。SQL SERVER不需要在硬盤上的數據一定要實際按照聚集索引排序,但在建立聚集索引時,會嘗試在邏輯上排序數據的同時,也會在物理上讓數據盡可能地排序。在索引子葉層級中的每個數據頁都有一個指針指向索引分頁的前一頁與后一頁,形成雙向鏈接串行,在內部的系統數據表包含了各索引子葉層第一個分頁的地址,為了保證數據在邏輯上是依照聚集索引的順序存放的,SQL SERVER 只需要由第一個分頁開始,并依照其連接串行一個接著一個依序尋找數據即可。如下圖。
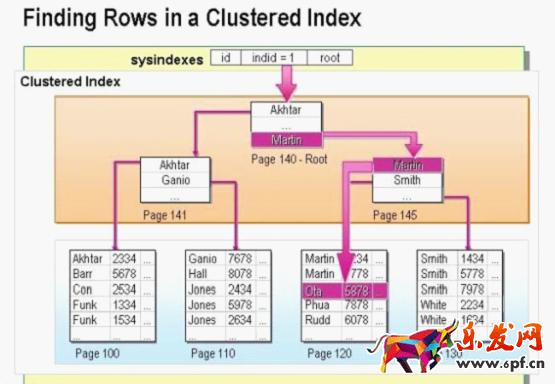
注:聚集表是有聚集索引的表。
非聚集索引
非聚集索引是完全獨立于數據表之外的結構,所以不會影響數據行的順序,其子葉層包含索引行。每個索引行包含非聚集鍵值、行定位符和任意包含列或非鍵列。行定位符中存入的數據有兩種類型:書簽(BOOKMARK)或聚集索引的鍵值。如果數據表上建立了聚集索引,則行定位符中存入的數據就是聚集索引的鍵值。如果數據表沒有建立聚集索引,則行定位符中存入的數據就是書簽,即指向數據表中記錄具體位置的ROWID,也就是文檔編號、分頁編號與頁內記錄編號(稱之為SOLT編號)所組合成的值。通過該ROWID 在數據表內獲取數據就稱為書簽查找 BOOKMARK LOOKUP。所以,一般通過非聚集索引查找到符合的鍵值后,還會搭配書簽查找。
當非聚集索引從結構中找到符合的記錄時,雖然在子葉層該鍵值是由小到大排序,因此可能在一個分頁上就有全部符合查詢條件的鍵值,但因為數據表中數據行的擺放是沒有按順序的(或是說沒有按照該非聚集索引的鍵值順序擺放),所以真正符合記錄的數據是散布在文檔各處的,而SQL SERVER每次讀取數據都是以數據頁為單位,因此,找到一條記錄所在位置后,要先將存放該條記錄的分頁讀到內存中,再從該頁讀出記錄。
因為BOOKMARK LOOKUP是進行隨機的I/O操作,當符合查詢的記錄很多時,通過非聚集索引訪問將導致數據頁讀取非常頻繁,就算兩條記錄在同一個分頁,該分頁也會被重復讀兩次,因此或符合的記錄有N條,就需要讀取數據表內的分頁N頁,雖然大部分的讀取操作都是針對內存中的高速緩存,但記錄數過多時一樣沒有效率,還不如數據表掃描,全部掃描一遍,把符合條件數據找出來。
雖然 SQL 2005 以后的版本中已經不在提 BOOKMARK LOOKUP了(但實際上卻是換湯不換藥),我們的很多搜索都是使用如下的搜索過程:先在非聚集中找,然后再在聚集索引中找。如下圖。

非聚集索引 ( Unclustered Index)
· 非聚集索引的頁,不是數據,而是指向數據頁的頁。
· 若未指定索引類型,則默認為非聚集索引
· 葉節點頁的次序和表的物理存儲次序不同
· 每個表最多可以有 249個非聚集索引(一般認為每個表不應該超過10個索引)
· 在非聚集索引創建之前創建聚集索引(否則會引發索引重建)
聚集索引與非聚集索引使用的情況:
|
動作描述
|
使用聚集索引
|
使用非聚集索引
|
|
外鍵列
|
應
|
應
|
|
主鍵列
|
應
|
應
|
|
列經常被分組排序(order by)
|
應
|
應
|
|
返回某范圍內的數據
|
應
|
不應
|
|
小數目的不同值
|
應
|
不應
|
|
大數目的不同值
|
不應
|
應
|
|
頻繁更新的列
|
不應
|
應
|
|
頻繁修改索引列
|
不應
|
應
|
|
一個或極少不同值
|
不應
|
不應
|
今天就普及一下索引的一些基本知識,明天來說明怎么選擇要創建索引的列,條件是什么,方法是什么。
樂發網超市批發網提供超市貨源信息,超市采購進貨渠道。超市進貨網提供成都食品批發,日用百貨批發信息、微信淘寶網店超市采購信息和超市加盟信息.打造國內超市采購商與批發市場供應廠商搭建網上批發市場平臺,是全國批發市場行業中電子商務權威性網站。
