

一、項目描述
該項目為一個咨詢項目,客戶為手機品牌商,主要目的是通過數據分析幫助制客戶制定品牌策略策略、產品策略和價格策略,助力客戶品牌的成長和銷量的增長。由于涉及到一些商業上的保密,所以本文最終公開的策略偏宏觀。
電商平臺為我們提供了大量的銷售數據,以及消費者的反饋數據,從電商平臺入手我們能夠同時了解到市場、產品和消費者,考慮到數據量以及用戶群體的豐富性,我們選擇了淘寶電商的數據作為我們的數據源。在項目中同時涉及到市場,產品和消費者,所以我們的思路是同時獲取到淘寶電商平臺上手機的銷售數據以及評論數據,然后通過數據挖掘,從評論中挖掘出產品的屬性特征和用戶特征并進行關聯,從而建立起市場、產品和消費者三者直接的聯系,然后進行數據分析,為我們幫助客戶制定品牌、產品以及價格策略提供依據。
二、數據采集
數據的采集上我們用python通過爬蟲的方式進行采集,思路為先模擬登錄淘寶,然后再通過關鍵字進行搜索,搜索后得到商品的列表,通過商品的列表信息,我們可以得到商品的id信息,得到id后我們通過把不同商品的id傳遞給不同的線程,通過多線程的方式同時爬取商品的銷售數據,評論數據和評分數據。
這里不再進行詳細的說明,有興趣的朋友可以參考具體代碼,鏈接(包括數據)如下
https://github.com/qmqqyb/-/tree/master?github.com/qmqqyb/-/tree/master
由于評論的文件太大,沒辦法上傳到github上,所以如果有朋友對評論數據感興趣的可以私信我。
三、數據挖掘
數據挖掘這一部分相對來說比較困難一些,我們主要是對評論數據進行了挖掘,挖掘兩個方面的信息,一個方面是評論的標簽(產品屬性+評論觀點),一部分是用戶分組信息,挖掘這兩部分信息的目的主要用這兩部分數據建立消費者的用戶畫像,同時把消費者和市場和產品關聯到一起,把評論信息結構化數值化,為后面的數據分析做準備。
在數據挖掘部分主要用到的一些技術和工具是:
哈工大ltp分詞、詞性標注、依存句法分析、命名實體識別、詞義角色標注;
Word2vect的gensim模塊進行詞向量計算;
k_mens聚類,得到用戶分組和產品的屬性,并為后面產品評論特征和用戶特征做歸一化做準備
具體大家可以參考如下代碼:
https://github.com/qmqqyb/comment_data_mining/tree/master?github.com/qmqqyb/comment_data_mining/tree/master
在鏈接的代碼中,涉及到的評論文本由于文件過大,暫時無法上傳,感興趣的朋友可以私信我。
四、數據分析
經過數據的挖掘和一些數據的處理,我們得到4491款不同手機數據信息,數據包含61個字段
(1)數據的理解
①首先導入數據,查看數據的基本信息
df = pd.read_csv('F:\pycharm project data\\taobao\phone\\final_goods_info.csv', encoding='utf-8', index_col=0)
print(df.columns)

這里我們可以把字段氛圍四類
第一類字段為一些基本的信息,主要包括以下
itemid:商品的id
category:商品的分類
sellerid:店鋪id
location:發貨地址
comment_count:評論數量
price:價格
sale_amount:銷售量
title:商品標題,標題中包括包含著品牌信息
sale_volume:產品的銷售額
第二類字段為產品的評論信息,主要包含電池、屏幕、音質等,其中在每個屬性下分為下標0和1.0表示negative評論,1表示positive評論,例如:
電池_0:該字段就表示電池負面評價字段,對應的數值表示評論中出現該標簽的頻數
電池_1:表示電池方面的正面評價,對應的數值表示評論中出現該標簽的頻數。
第三類字段為用戶信息分字段,用戶信息字段根據年齡和角色,兩個字段
年齡分組中:主要包含兒童、青年、中年和老年人這些值
角色分組中:主要包含學生,爸爸,媽媽、女朋友、男朋友這些信息
第四類字段只包含一個字段,主要是用戶對該產品的評分
score:用戶對商品的評分,5分為滿分
(2)數據的清洗以及數據的處理
①缺失值的填充
對于數值型的數據,缺失值主要集中在評論頻次上,評論頻次的缺失主要由于該商品沒有涉及到該品論標簽,所以我們可以直接填充為0.這樣也方便我們后續的數據類型的轉化;
df.fillna(0. inplace=True)
然后我們需要將頻次的數據轉化為以及其他一些有實際意義的數字轉化為int型
cols = ['itemid', 'category', 'sellerId', 'isTmall', 'comment_count', '系統很強大', '手機不錯', '用得久', '手機一般', '電池_1', '電池_0', '信號_1', '信號_0', '性價比_1', '功能_1', '功能_0', '音質_1', '音質_0', '屏幕_1', '屏幕_0', '正品_1', '軟件_1', '軟件_0', '按鍵_1', '按鍵_0', '外觀_1', '外觀_0', '拍照_1', '拍照_0', '手感_1', '死機_1', '配件_1', '配件_0', '包裝_1', '贈品_1', '贈品_0', '物流_1', '物流_0', '視頻_1', '發熱_1', '發熱_0', '輕便_1', '操作_1', '性價比_0', '正品_0', '手感_0', '死機_0', '包裝_0', '總體_1', '總體_0', '視頻_0', '輕便_0', '操作_0']
for col in cols:
df[col] = df[col].astype('int64')
對于用戶分組的信息,如果發生缺失則代表,該商品中沒有提及到手機適合的用戶對象,所以我們用空值進行填充
df.loc[df['年齡分組'] == 0. ['年齡分組']] = ''
df.loc[df['角色分組'] == 0. ['角色分組']] = ''
②異常值的處理
首先我們來看價格,我們做一各品牌手機價格的箱線圖:
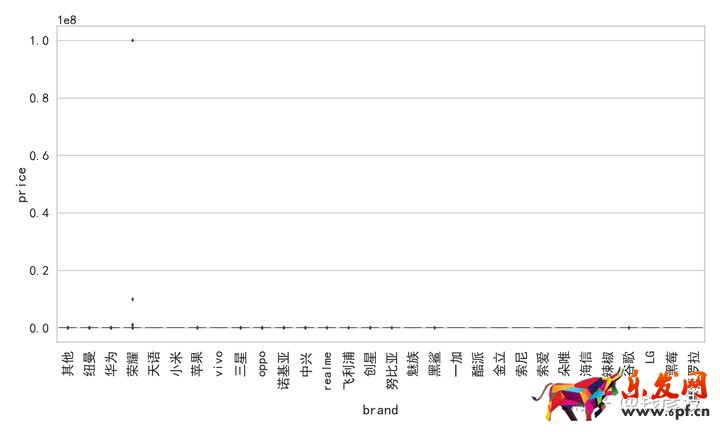
我們可以發現,榮耀手機的價格接近100000.導致箱線圖其他數據在圖中直接沒有顯示出來,但是我們查看其銷售量卻為0.所以這類數據是存在異常的,我們使用分位數的方法來去除異常數據:
# 用分位數法去除異常值
high_q = df['price'].quantile(q=0.75)# 上四分位數
low_q = df['price'].quantile(q=0.25)# 下四分位數
interval = (high_q - low_q)# 分位數間隔
df = df.loc[(df['price'] > low_q - 3*interval) & (df['price'] < high_q + 3*interval), ]
去除異常數據之后,我們再來看一下各品牌手機的價格情況:
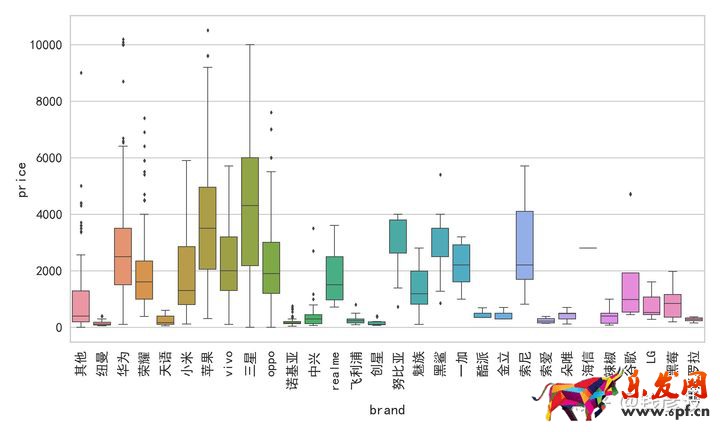
從上圖中可以看出,進行處理以后手機的價格基本位于11000元以下,符合我們的預期。
③數據分箱
為了方便我們后續的研究,我們對價格數據進行分箱處理
# 對價格進行分箱處理
labels = list(np.arange(60))
counts, bins_edge = np.histogram(df['price'], bins=60)
df['分組'] = pd.cut(df['price'], bins=bins_edge, labels=labels, include_lowest=True)
price_list = []
for bin_price in bins_edge:
price_list.append(round(bin_price, 1))
df['分組'] = pd.cut(df['price'], bins=bins_edge, labels=labels, include_lowest=True)
plt.figure(figsize=(20. 10))
sns.barplot(x=price_list[1: 61], y=counts)
plt.xticks(rotation=90)
plt.ylabel('count')
plt.title('price')
plt.show()
結果如下:

注意這里的橫軸表示每個價格小區間,如175.0代表0-175的價格,縱軸表示位于該價格區間中的商品數量。為了在后面表示方便,我們用0-59的標簽來代表每個價格小區間。
(3)市場分析
首先根據價格分組我們可以得到價格和銷量,價格和銷售額之間的關系,如下:
# 按照價格分組數據進行切分
gp_df = df.groupby('分組')
# 價格和銷量的曲線圖
g_sales_amount = gp_df['sales_amount'].agg(sum)
plt.figure(figsize=(20. 12))
sns.pointplot(x=np.arange(60), y=g_sales_amount.values[0: 60], color='r')
plt.title('price-sales_amount')
plt.xlabel('price')
plt.xticks(rotation=90)
plt.ylabel('sales_amount')
plt.show()
# 價格和銷售量的關系
g_sales_volume = gp_df['sales_volume'].agg(sum)
plt.figure(figsize=(20. 12))
sns.pointplot(x=np.arange(60), y=g_sales_volume.values[0: 60], color='r')
plt.title('price-sales_volume')
plt.xlabel('price')
plt.xticks(rotation=90)
plt.ylabel('sales_volume')
plt.show()
# print(bins_edge)
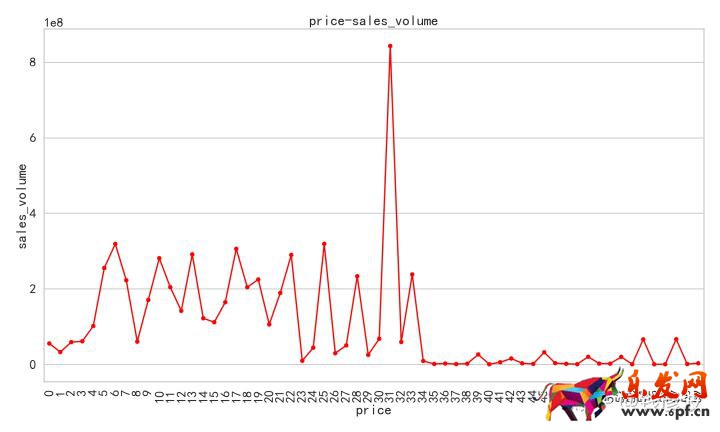
對比價格和銷量,價格和銷售額的的關系,我們可以得出以下信息:
①價格和銷售額以及銷售量的關系都呈現出復雜的脈沖關系;
②在價格和銷量的關系中出現了三個顯著的波峰位置,一個位置是0.對應0-175元的價格區間;一個位置是6.對應1049.9-1224.9元的價格區間;一個是31的位置,對應的是5424.5-5599.5元的價格區間;
③在價格和銷售額的關系中出現了兩個最顯著的波峰位置,一個是6對應1049.9-1224.9元的價格區間,在價格低于1224.9這個區間內,價格和銷售額呈現出正相關的關系;另一個是31的位置,對應的是5424.5-5599.5元的價格區間,在價格高于5599.5這個價位的時候銷售額明顯急劇下降。
④在6-31的位置區間內不管是銷售量還是銷售額都呈現出反復脈沖的關系。
所以我們發現銷量和銷售額隨著價格的變動情況只有在0這個位置上差異非常大,我們把這一部分產品篩選出來查看一下,發現這是因為處于0-175這個價位的有一些老年機和兒童手表電話賣的特別火,但是由于價格較低,其本身銷售額和手機比還是差很多,現在我們把這一部分的數據剔除得到如下關系:
# 舍去價格位于0-175的價位之間的產品
df = df.loc[df['分組'] != 0. ]
# 按照價格分組數據進行切分
gp_df = df.groupby('分組')
# 價格和銷量的曲線圖
g_sales_amount = gp_df['sales_amount'].agg(sum)
plt.figure(figsize=(20. 12))
sns.pointplot(x=np.arange(60), y=g_sales_amount.values[0: 60], color='r')
plt.title('price-sales_amount')
plt.xlabel('price')
plt.xticks(rotation=90)
plt.ylabel('sales_amount')
plt.show()
# 價格和銷售量的關系
g_sales_volume = gp_df['sales_volume'].agg(sum)
plt.figure(figsize=(20. 12))
sns.pointplot(x=np.arange(60), y=g_sales_volume.values[0: 60], color='r')
plt.title('price-sales_volume')
plt.xlabel('price')
plt.xticks(rotation=90)
plt.ylabel('sales_volume')
plt.show()
# print(bins_edge)
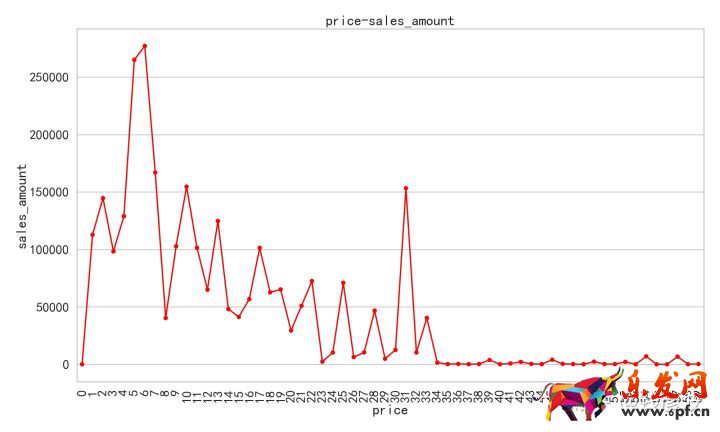
我們現在可以發現,當剔除了0-175之間特殊消費的影響后,銷售額和銷售量隨價格波動的具有非常高的一致性,仍然有兩個關鍵的位置,一個位置是6.對應1049.9-1224.9元的價格區間;一個是31的位置,對應的是5424.5-5599.5元的價格區間。價格低于1224.9時,銷量和銷售額隨著價格的升高而升高;當價格位于1224.9-5424.5元區間內時,價格和銷售量和銷售額之間都呈現出反復脈沖的關系;當價格為5424.5-5599.5元區間內的時候銷售額和銷售量都出現顯著的波峰;當價格高于5599.5元的時候,銷售量和銷售額都隨著價格升高急劇下降。
所以按照這樣的關系,我們可以把手機市場切分了三個市場,一個是1225元以下,我們稱之為低端市場,一個是1225-5425元之間,我們稱之為中端市場;一個是5425元以上,我們稱之為高端市場。

根據市場分析,我們首先來看一下各個市場的銷售額和銷售量的分布情況:
# 總體市場分析
df['市場分組'] = ''
df.loc[df['分組'].isin(list(np.arange(0. 7))), ['市場分組']] = 'low_market'
df.loc[df['分組'].isin(list(np.arange(7. 31))), ['市場分組']] = 'medium_market'
df.loc[df['分組'].isin(list(np.arange(31. 60))), ['市場分組']] = 'high_market'
print(df.head(100))
market_a_df = df.groupby('市場分組')['sales_amount'].sum().sort_values(ascending=False)
market_v_df = df.groupby('市場分組')['sales_volume'].sum().sort_values(ascending=False)
# 市場銷售額和銷售量分析
plt.figure(figsize=(10. 10))
plt.pie(market_a_df, labels=market_a_df.index, autopct="%1.1f%%")
plt.title('market_amount')
plt.show()
plt.figure(figsize=(10. 10))
plt.pie(market_v_df, labels=market_v_df.index, autopct="%1.1f%%")
plt.title('market_volume')
plt.show()

對比銷售額和銷售量在各個市場中的占比情況,我們可以得到以下信息:
低端市場中的銷售量占優勢,但是由于價格過低,在營收方面占比最少,而中端市場依靠42.6%的市場銷量,創造了62.7%的市場營收,高端市場依靠6.9%的市場銷量,創造了23.0%的市場營收。
主要原因是低端市場的價格太低,雖然在銷量上占優,但是在營收上遠遠低于中端市場和高端市場中。但是我們重點應該關注的是低端市場高銷量背后,是否隱藏著商業機會?
針對這個問題,我們來看一下,低端市場中的用戶群體:
# 低端市場用戶分布研究
low_df = df.loc[df['分組'].isin(list(np.arange(0. 7))), ]
g_low_df = low_df.groupby('年齡分組')['sales_amount'].sum().sort_values(ascending=False)
# 低端市場的用戶分布
plt.figure(figsize=(10. 10))
plt.pie(g_low_df, labels=g_low_df.index, autopct="%1.1f%%")
plt.title('low_market_user')
plt.show()
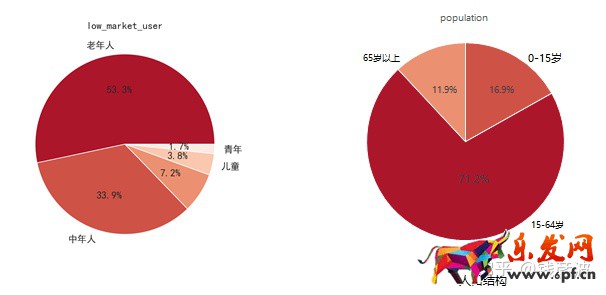
在上面的圖中,左邊是低端市場中用戶按照年齡分類后的分布情況,右邊是我國目前的人口結構中的年齡分布情況。對比我們可以發現在低端市場中,主要是老年人用戶群體,占比超過53.3%,這非常符合我們的預期。但是我們也要注意到,按照低端市場在總市場占比50.5%,低端市場的用戶中年人占比33.9%,中年人在我國人口結構中占比71.2%來計算,這部分中年人用戶是一個龐大的基數。那這部分中年人的消費為什么會在低端市場?
針對這個問題,我們來看一下中年人用戶的一些消費偏好:
# 低端市場中年人用戶畫像研究
cols = ['系統很強大', '手機不錯', '用得久', '手機一般', '電池_1', '電池_0', '信號_1', '信號_0', '性價比_1', '功能_1', '功能_0', '音質_1', '音質_0', '屏幕_1', '屏幕_0', '正品_1', '軟件_1', '軟件_0', '按鍵_1', '按鍵_0', '外觀_1', '外觀_0', '拍照_1', '拍照_0', '手感_1', '死機_1', '配件_1', '配件_0', '包裝_1', '贈品_1', '贈品_0', '物流_1', '物流_0', '視頻_1', '發熱_1', '發熱_0', '輕便_1', '操作_1', '性價比_0', '正品_0', '手感_0', '死機_0', '包裝_0', '總體_1', '總體_0', '視頻_0', '輕便_0', '操作_0']
# 進行用戶分組分析
g_low_um_df = low_df.loc[df['年齡分組'] == '中年人', cols].sum(axis=0).sort_values(ascending=False)
# 中年人用戶關注性能分析
plt.figure(figsize=(10. 10))
plt.pie(g_low_um_df[0: 10], labels=g_low_um_df.index[0: 10], autopct="%1.1f%%")
plt.title('low_muser_point')
plt.show()
#中年人品牌分析
bm_df = low_df.loc[df['年齡分組'] == '中年人']
g_low_bm_df = bm_df.groupby('brand')['sales_amount'].sum().sort_values(ascending=False)
# 中年人用戶品牌分析
plt.figure(figsize=(10. 10))
plt.pie(g_low_bm_df[0: 8], labels=g_low_bm_df.index[0: 8], autopct="%1.1f%%")
plt.title('low_muser_brand')
plt.show()
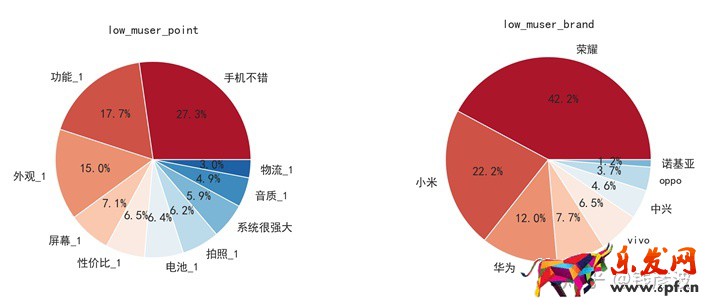
在上面的圖中,左邊是中年人用戶對手機某方面屬性關注的占比情況,右邊為中年人用戶對品牌的偏好。可以發現中年人用戶更為關注手機的整體性能,以及外觀方面的屬性,更青睞于榮耀,華為和小米三個品牌。(注意這里把榮耀和華為拆開是為了后面的對比方便)
現在我們來看一下低端市場的用戶畫像:
# 低端市場用戶畫像研究
cols = ['系統很強大', '手機不錯', '用得久', '手機一般', '電池_1', '電池_0', '信號_1', '信號_0', '性價比_1', '功能_1', '功能_0', '音質_1', '音質_0', '屏幕_1', '屏幕_0', '正品_1', '軟件_1', '軟件_0', '按鍵_1', '按鍵_0', '外觀_1', '外觀_0', '拍照_1', '拍照_0', '手感_1', '死機_1', '配件_1', '配件_0', '包裝_1', '贈品_1', '贈品_0', '物流_1', '物流_0', '視頻_1', '發熱_1', '發熱_0', '輕便_1', '操作_1', '性價比_0', '正品_0', '手感_0', '死機_0', '包裝_0', '總體_1', '總體_0', '視頻_0', '輕便_0', '操作_0']
# 進行用戶分組分析
g_low_u_df = low_df[cols].sum(axis=0).sort_values(ascending=False)
# 低端市場用戶關注性能分析
plt.figure(figsize=(10. 10))
plt.pie(g_low_u_df[0: 10], labels=g_low_u_df.index[0: 10], autopct="%1.1f%%")
plt.title('low_user_point')
plt.show()
#低端市場品牌分析
g_low_m_df = low_df.groupby('brand')['sales_amount'].sum().sort_values(ascending=False)
# 中年人用戶品牌分析
plt.figure(figsize=(10. 10))
plt.pie(g_low_m_df[0: 8], labels=g_low_m_df.index[0: 8], autopct="%1.1f%%")
plt.title('low_user_brand')
plt.show()

我們可以發現低端市場中的用戶畫像和低端市場中中年人的用戶畫像差距非常大,在手機的屬性方面,低端市場的用戶更為關注的是手機的音質、功能(手機的基本功能,例如電打電話、上網等)方面的屬性,這與低端市場中老年人占比較多有關;品牌的偏好上,低端市場的用戶出現了一些不知名的小品牌,榮耀也占一定的比例。
現在我們來看一些中端市場的用戶畫像:
# 中端市場用戶畫像研究
cols = ['系統很強大', '手機不錯', '用得久', '手機一般', '電池_1', '電池_0', '信號_1', '信號_0', '性價比_1', '功能_1', '功能_0', '音質_1', '音質_0', '屏幕_1', '屏幕_0', '正品_1', '軟件_1', '軟件_0', '按鍵_1', '按鍵_0', '外觀_1', '外觀_0', '拍照_1', '拍照_0', '手感_1', '死機_1', '配件_1', '配件_0', '包裝_1', '贈品_1', '贈品_0', '物流_1', '物流_0', '視頻_1', '發熱_1', '發熱_0', '輕便_1', '操作_1', '性價比_0', '正品_0', '手感_0', '死機_0', '包裝_0', '總體_1', '總體_0', '視頻_0', '輕便_0', '操作_0']
# 進行用戶分組分析
medium_df = df.loc[df['分組'].isin(list(np.arange(7. 31))), ]
g_medium_u_df = medium_df[cols].sum(axis=0).sort_values(ascending=False)
# 低端市場用戶關注性能分析
plt.figure(figsize=(10. 10))
plt.pie(g_medium_u_df[0: 10], labels=g_medium_u_df.index[0: 10], autopct="%1.1f%%")
plt.title('medium_user_point')
plt.show()
#中端市場品牌分析
g_medium_m_df = medium_df.groupby('brand')['sales_amount'].sum().sort_values(ascending=False)
# 中年人用戶品牌分析
plt.figure(figsize=(10. 10))
plt.pie(g_medium_m_df[0: 8], labels=g_medium_m_df.index[0: 8], autopct="%1.1f%%")
plt.title('medium_user_brand')
plt.show()
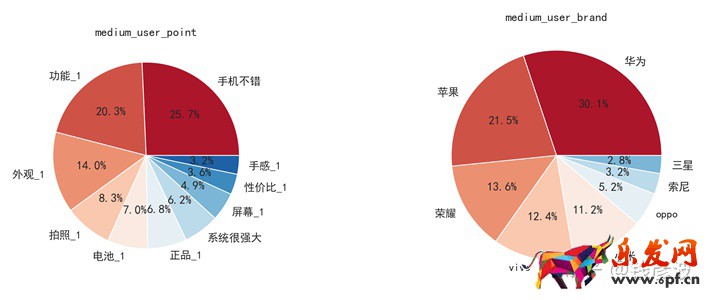
對比中端市場用戶的畫像和低端市場中中年人的用戶畫像,可以發現在手機的屬性方面,中端市場用戶和低端市場中年人的用戶關注點近似,都是產品的功能(手機的基本功能,例如電打電話、上網等)、外觀、電池、拍照等;在品牌偏好上蘋果的價位較高,沒有千元機,所以低端市場的中年人用戶沒有選擇權,但對華為、榮耀、小米幾個品牌商認同度接近。
通過中年人用戶的對比我們發現一下幾點信息:
①低端市場中中年人用戶占比較大,按照低端市場銷量占比和中年人人口占比來計算,這是一個龐大的消費群體;
②單獨分析低端市場中年人用戶的畫像,發現其和低端市場整體用戶畫像差異較大而和中端市場整體用戶畫像差異較小;
③基于以上兩點,我們判斷,低端市場中的這一部分中年人的消費需求理應在中端市場,但是由于某種原因使得他們只能選擇低端市場;
④中端市場和低端市場最顯著的區別就是低端市場的整體價格比中端市場要低很多,所以我們可以判斷低端市場中中年人這個群體的消費需求整體上受到收入上的抑制,并沒有充分釋放出來,在收入保持穩定增長的前提下,未來中端市場的存在繼續壯大發展的潛力。
(4)中端市場產品和價格分析
在了解了中端市場存在著巨大的發展潛力后,如何壯大自己品牌在中端市場的競爭力呢?
針對這個問題,我們首先再來看一下中端市場價格和銷售量以及銷售額的關系:
# 中端市場分析
gp_df = df.groupby('分組')
# 價格和銷量的曲線圖
g_sales_amount = gp_df['sales_amount'].agg(sum)
plt.figure(figsize=(20. 12))
sns.pointplot(x=np.arange(7. 31), y=g_sales_amount.values[7: 31], color='r')
plt.title('price-sales_amount')
plt.xlabel('price')
plt.xticks(rotation=90)
plt.ylabel('medium_sales_amount')
plt.show()
# 價格和銷售額的關系
g_sales_volume = gp_df['sales_volume'].agg(sum)
plt.figure(figsize=(20. 12))
sns.pointplot(x=np.arange(7. 31), y=g_sales_volume.values[7: 31], color='r')
plt.title('price-sales_volume')
plt.xlabel('price')
plt.xticks(rotation=90)
plt.ylabel('medium_sales_volume')
plt.show()
可以發現中端市場的價格和銷售額以及銷售量都存在著反復脈沖的復雜關系,那為什么會呈現出這種關系呢?
我們來觀察一下中端市場的消費者群體:
# 中端市場用戶研究
g_medium_df = medium_df.groupby('年齡分組')['sales_amount'].sum().sort_values(ascending=False)
# 低端市場的用戶分布
plt.figure(figsize=(10. 10))
plt.pie(g_medium_df, labels=g_medium_df.index, autopct="%1.1f%%")
plt.title('medium_market_user')
plt.show()
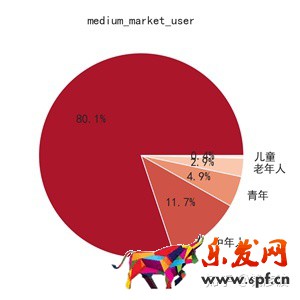
上圖是中端市場用戶的一個分布圖,由于我們在從評論中挖掘用戶信息的時候,主要是挖掘在評論中提及到的對象,比如某條評論中可能會提及到手機適合老人使用,那么我們就可以挖掘到老人這個用戶信息,但是對于大部分給自己買手機的消費者來說,不會表明自己的身份,只會對產品本身加以評論,所以圖中缺失的80.1%的用戶信息主要集中在中青年,有獨立的消費能力的人群中。
對于以中青年為主的中端市場,消費者有什么樣的消費偏好呢:
我們來看中端市場的用戶畫像:
對比以上兩個圖,我們可以得到以下幾點信息:
①中端市場的用戶除了關注手機整體性能這種通用屬性外,更加關注手機的外觀、拍照、電池、是否正品等方面的屬性;
②在品牌商中端市場的品牌偏好呈現多元化,華為、榮耀、vivo、小米、oppo等主要的品牌都占有一定的市場份額;
我們可以看到中端市場的用戶不管是在產品屬性還是品牌上,消費需求非常的多元化,這就很好地解釋了為什么為什么中端市場在會出現反復脈沖的關系。由于用戶消費需求的多元化,所以品牌商為了滿足不同消費群體的個性化需求,利用產品設計和價格的多元化變相實施價格歧視,達到利潤的最大化,所以基本在一定的價格區間內就會出現一次銷量和銷售額的急劇上升,中端市場是一個多層次的市場。
為了這一結論更加可靠,我們可以從品牌的價格競爭策略上做一個橫向對比:
# 中端市場價格多元化與銷售量的關系
pro_list = ['華為', '蘋果', '小米', '榮耀', 'oppo', 'vivo', '三星']
g_b_medium_df = medium_df.groupby('brand')['price']
price_sum_list = []
for i in range(len(pro_list)):
b_df = g_b_medium_df.get_group(pro_list[i]).value_counts()
price_sum_list.append(len(b_df))
# print(price_sum_list)
plt.figure(figsize=(12. 8))
sns.barplot(x=pro_list, y=price_sum_list)
plt.title('medium_market_brand_price')
plt.show()
g_b_medium_volume_df = medium_df.groupby('brand')['sales_volume']
volume_sum_list = []
for i in range(len(pro_list)):
b_df = g_b_medium_df.get_group(pro_list[i]).sum()
volume_sum_list.append(b_df)
# print(price_sum_list)
plt.figure(figsize=(12. 8))
sns.barplot(x=pro_list, y=volume_sum_list)
plt.title('medium_market_brand_volume')
plt.show()

在上圖中,左邊的圖表示在中端市場中每個品牌手機制定的價格數量,右邊的圖表示每個品牌手機在中端市場中的銷售額,我們可以很明顯的看出一致性非常強,既制定價格數越多的品牌,其對應的銷售額就越多,這也很好的證明了我們上面的結論。
所以,在未來,手機廠商們應該重點把握中端市場仍未飽和的機會,注重以年輕用戶喜歡拍照,注重產品外觀,看中產品是否為正品等方面的性能為導向,打造個性化、多樣化的產品,制定多元化的價格策略,并制定一定的品牌驗證機制,實現營收上的增長。
(5)高端市場產品和價格
高端市場在總的市場占比中超過20%,那么高端市場是否存在機會呢?
我們先來看一下高端市場的用戶分布情況:
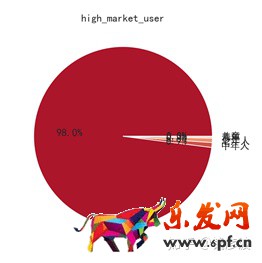
上圖是高端市場用戶的一個分布圖,和中端市場類似,由于我們在從評論中挖掘用戶信息的時候,主要是挖掘在評論中提及到的對象,比如某條評論中可能會提及到手機適合老人使用,那么我們就可以挖掘到老人這個用戶信息,但是對于大部分給自己買手機的消費者來說,不會表明自己的身份,只會對產品本身加以評論,所以圖中缺失的98.0%的用戶信息主要集中在中青年,有獨立的消費能力的人群中。
接著我們來看高端市場用戶畫像:
# 高端市場用戶畫像研究
high_df = df.loc[df['分組'].isin(list(np.arange(31. 60))), ]
cols = ['系統很強大', '手機不錯', '用得久', '手機一般', '電池_1', '電池_0', '信號_1', '信號_0', '性價比_1', '功能_1', '功能_0', '音質_1', '音質_0', '屏幕_1', '屏幕_0', '正品_1', '軟件_1', '軟件_0', '按鍵_1', '按鍵_0', '外觀_1', '外觀_0', '拍照_1', '拍照_0', '手感_1', '死機_1', '配件_1', '配件_0', '包裝_1', '贈品_1', '贈品_0', '物流_1', '物流_0', '視頻_1', '發熱_1', '發熱_0', '輕便_1', '操作_1', '性價比_0', '正品_0', '手感_0', '死機_0', '包裝_0', '總體_1', '總體_0', '視頻_0', '輕便_0', '操作_0']
# 進行用戶分組分析
g_high_u_df = high_df[cols].sum(axis=0).sort_values(ascending=False)
# 高端市場用戶關注性能分析
plt.figure(figsize=(10. 10))
plt.pie(g_high_u_df[0: 10], labels=g_high_u_df.index[0: 10], autopct="%1.1f%%")
plt.title('high_user_point')
plt.show()
#中端市場品牌分析
g_high_m_df = high_df.groupby('brand')['sales_amount'].sum().sort_values(ascending=False)
# 中年人用戶品牌分析
plt.figure(figsize=(10. 10))
plt.pie(g_high_m_df[0: 5], labels=g_high_m_df.index[0: 5], autopct="%1.1f%%")
plt.title('high_user_brand')
plt.show()
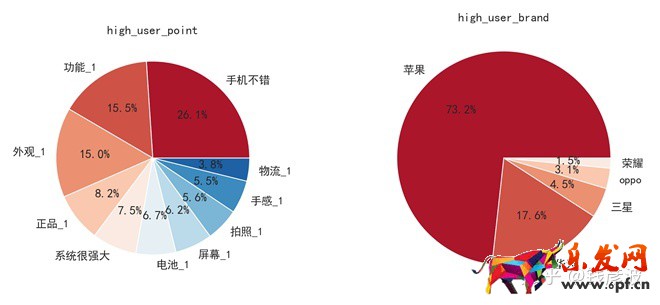
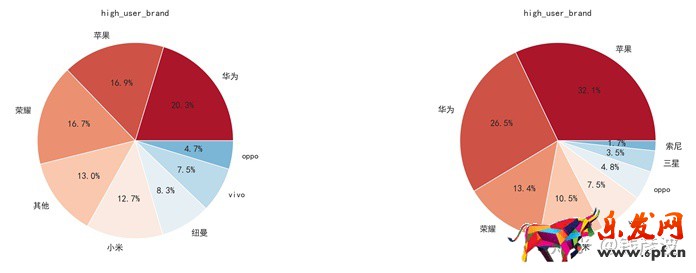
上圖中左邊為高端市場中用戶關注的手機屬性分布情況,右圖為高端市場的用戶對品牌的偏好分布情況,對比后我們發現:
①區別于中低端市場,高端市場中,用戶除了關注手機的一些通用屬性外,更為關注產品的外觀以及是否為正品;
②高端市場中品牌的集中度非常高,蘋果的銷量占比超過70%,華為和三星占一定比例。
對于高端市場而言,是否存在中端市場中的價格多元化以及銷售額正相關的關系呢?
我們來看高端市場中制定各品牌制定的價格數量和銷售額之間的關系:
# 高端市場價格多元化與銷售量的關系
pro_list = ['華為', '蘋果', '小米', '榮耀', 'oppo', 'vivo', '三星']
g_b_high_df = high_df.groupby('brand')['price']
price_sum_list = []
for i in range(len(pro_list)):
b_df = g_b_high_df.get_group(pro_list[i]).value_counts()
price_sum_list.append(len(b_df))
# print(price_sum_list)
plt.figure(figsize=(12. 8))
sns.barplot(x=pro_list, y=price_sum_list)
plt.title('high_market_brand_price')
plt.show()
g_b_high_volume_df = high_df.groupby('brand')['sales_volume']
volume_sum_list = []
for i in range(len(pro_list)):
b_df = g_b_high_df.get_group(pro_list[i]).sum()
volume_sum_list.append(b_df)
# print(price_sum_list)
plt.figure(figsize=(12. 8))
sns.barplot(x=pro_list, y=volume_sum_list)
plt.title('high_market_brand_volume')
plt.show()
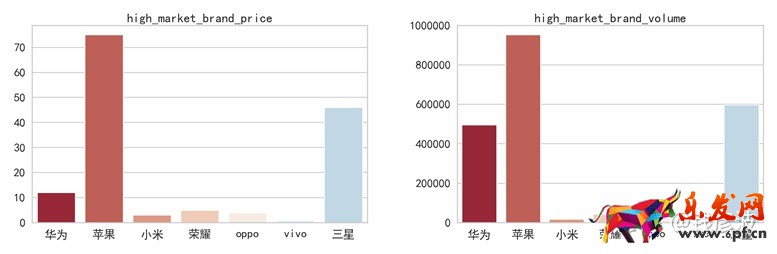
在上圖中,左邊的圖表示在高端市場中每個品牌手機制定的價格數量,右邊的圖表示每個品牌手機在高端市場中的銷售額,我們可以很明顯的看出華為在高端市場中價格制定相對比較集中,但是其在銷售額上仍然表現比較好,這其實反映了華為進入高端市場是相對比較謹慎的。
那高端市場對于一個追求營收最大化的品牌來說,應不應該重點布局呢?
我們這里先看一下各品牌的市場占比以及均價其情況:
# 銷量和銷售額分析
g_a_df = df.groupby('brand')['sales_amount'].sum().sort_values(ascending=False)
g_v_df = df.groupby('brand')['sales_volume'].sum().sort_values(ascending=False)
# 銷售量
plt.figure(figsize=(12. 12))
plt.pie(g_a_df[0: 8], labels=g_a_df.index[0: 8], autopct="%1.1f%%")
plt.title('high_user_brand')
plt.show()
# 銷售額
plt.figure(figsize=(12. 12))
plt.pie(g_v_df[0: 8], labels=g_v_df.index[0: 8], autopct="%1.1f%%")
plt.title('high_user_brand')
plt.show()
在上圖中,左邊的圖表示各品牌的銷量占比,右邊的圖表示每個品牌手機銷售額占比。結合三星在中高端市場多元化的價格策略分析,我們發現盡管三星在中端市場和高端市場中實施了多元化的價格策略,但是從整體上來看,中高端市場的價格多元化戰略并沒有給三星帶來整體市場在銷量以及銷售額上的提升。這是什么原因造成的呢?
對比三星在中端市場和高端市場制定價格和銷售額的關系,我們發現,三星在高端市場多元化的價格戰略實際上帶來了銷售的增長,但是在中端市場中三星的價格多元化戰略明顯比較失敗,因為小米、榮耀、vivo、oppo制定的價格數量都小于三星,但是在銷售額上卻要比三星的占比要高,最終從整個市場來看,榮耀、vivo、小米、oppo的銷售額都高于三星。
那為什么三星會在中端市場遭遇滑鐵盧呢?
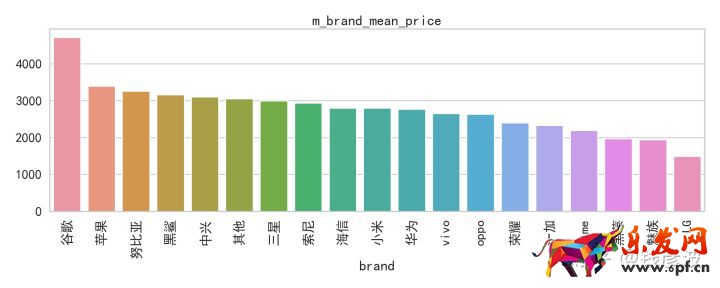
我們來看一下中端市場各品牌手機的均價:
# 各品牌均價
g_mp_df = medium_df.groupby('brand')['price'].mean().sort_values(ascending=False)
plt.figure(figsize=(20. 8))
sns.barplot(x=g_mp_df.index, y=g_mp_df.values)
plt.xticks(rotation=90)
plt.title('m_brand_mean_price')
plt.show()
我們可以看出在中端市場,銷售額占比較大的幾個品牌除了蘋果外,華為、小米、榮耀、oppo、vivo的價格均低于三星。
從整體上來看,在中端市場中三星雖然價格也比較多元化,但是,第一品牌弱于蘋果,第二價格高于華為、小米、榮耀、oppo、vivo,所以導致三星在中端市場從品牌和價格上都不占優勢,在中端市場中的銷量和營收占比都較低。這是三星在戰略上的失誤,三星并沒有在中端市場取穩固,取得優勢的前提下,再進入高端市場。
而相對來說國內的品牌華為在中端市場穩固的前提下非常謹慎地進入高端市場,并取得了一定的成效。vivo基本上沒有進攻高端市場,繼續做大坐穩中端市場,并在2019年中市占率超過了oppo。oppo正在嘗試進入高端市場,中端市場的穩固性出現一定的調整。小米也在嘗試進入高端市場,但是成效并不理想。
所以我們發現中端市場,對于一個品牌來說,不管是市場的穩固,還是發展機遇都非常重要,對于高端市場,品牌的壁壘非常強,用戶對品牌的認可度非常高,不應該在中端市場得不到穩固的情況下貿然進入。
(7)策略建議
①中端市場在未來仍然存在著較大的市場發展空間,品牌商應該把握住中端市場的機會,進一步鞏固自己的市場地位。
②對于中端市場中競爭的各大品牌來說,應該聚焦于消費者最關心的性能,重點打造差異化個性化產品,建立起與其他品牌的競爭優勢,為品牌創收,并形成品牌標簽,增強品牌的傳播力度,同時為品牌的升級奠定市場基礎和消費心理需求。
③在中端市場中,消費者對品牌的認可度相對來說不高,消費者更加關注產品的性能和價格,對應的應該實施更為多元化的價格策略。
④目前國產品牌在中端市場占有絕對的優勢,對于華為來說,高端市場的進入取得了初步的成效,但是仍然需要注意防守中端市場;對于oppo和小米來說,中端市場有一定程度的下降,進入高端市場需要謹慎,不能急于求成,一定要穩固好中端市場;對于vivo來說,在中端市場得到強化的同時,應該逐步打造幾款特征鮮明的產品,嘗試進入高端市場。
⑤在高端市場,用戶的品牌忠誠度非常高,品牌壁壘效應強,不應該在中端市場得不到穩固的情況下貿然進入。
⑥對于已經進入高端市場的品牌來說,需要建立品牌驗證機制,同時和子品牌建立一定的品牌隔離,保證高端市場用戶的消費體驗。
⑦在低端市場中,能夠通過打造一些剛需產品,迅速拓展品牌的銷量,所以對于其他小品牌來說,品牌的塑造應該從中低端市場切入,在低端市場打造高性價比的剛需產品,擴大品牌受眾;在中端市場打造差異化、個性化的產品為品牌創收,強化自己的市場地位。
樂發網超市批發網提供超市貨源信息,超市采購進貨渠道。超市進貨網提供成都食品批發,日用百貨批發信息、微信淘寶網店超市采購信息和超市加盟信息.打造國內超市采購商與批發市場供應廠商搭建網上批發市場平臺,是全國批發市場行業中電子商務權威性網站。
本文來源: 淘寶電商數據挖掘與分析


